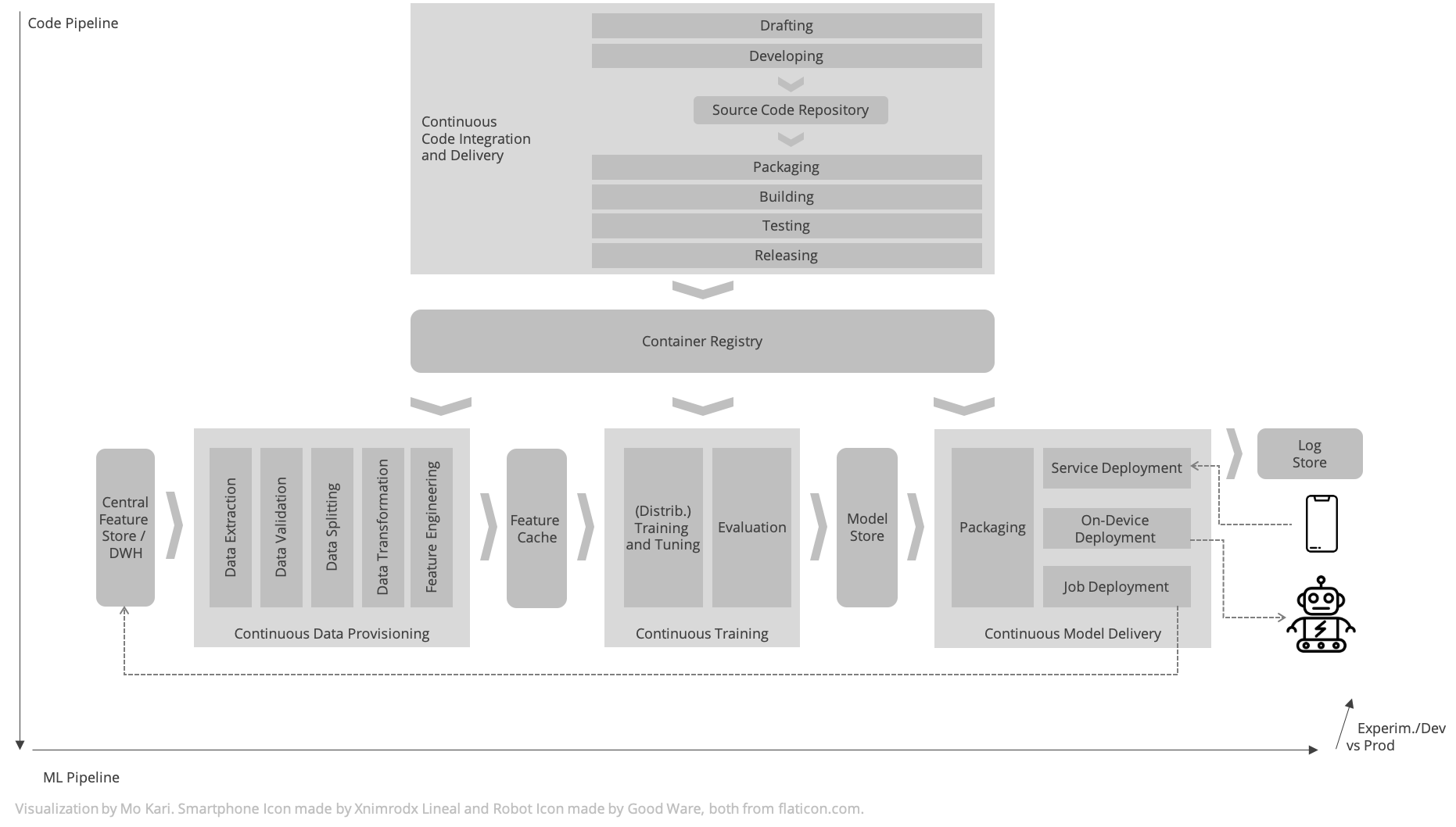
Most “frameworks for bringing ML into production” only cover part of the picture. Let’s try to take a step back and make sense of the different framework-agnostic facets of MLOps, namely Continuous Code Integration and Delivery, Continuous Data Provisioning, Continuous Training, and Continuous Delivery.
TL;DR
A picture’s worth a thousand words:
ML applications and models
An instance of a machine learning application is characterized 1 by
- the model code and model hyperparameters used to learn the model parameters, run inferences, and evaluate them, and
- the data used to learn the model parameters, that is used to produce a serialized model including its structure and parameters.
I understand a model as the combination of model code and the serialized model including its structure parameters and its parameters A single version of model code can be used to produce different model parameters, e. g. by modifying the length of the training, modifying the model hyperparameters, or modifying the model data used for training. Model code is also used to evaluate the model parameters and to serve the model. Changing either the model code or the model parameters results in a new model version.
Key aspects against which MLOps infrastructure is to be designed include:
- different machine learning paradigms that are not limited to supervised learning
- experimenting with different features, algorithms, hyperparameter configurations, resulting in different qualities that need to be tracked and reproduced
- externally controlled time-variant factors of quality namely that the application quality is subject to changes in the training data distribution and production data distribution thus requiring data schema and distribution assumption validation, continuous training, and performance monitoring.
- interdisciplinary teams comprising subject matter experts, data engineers, data scientists, and ML engineers
Components of MLOps
Continuous Code Integration and Delivery
MLOps infrastructure should allow drafting, developing, packaging, building, testing, releasing, and version-controlling model code that comprises components for loading datasets and verifying assumptions against it, engineering features from the provisioned dataset, learning parameters through training, validation, and tuning, validating the model against the test data, serving the model for backend-based inference services or batch inference, or building a deployable model artifact for embedded inference.
Generally, model code is packaged as a Docker container. Apart from the automated code integration and delivery pipeline, for drafting model code, notebook environments and interactive visualization tools play a central role.
Continuous Data Provisioning
MLOps infrastructure should allow provisioning feature datasets through an automated data provisioning pipeline that comprises steps for data extraction, data validation, data splitting, data transformation, and feature engineering. In supervised learning scenarios these training, validation, and test features comprise input features and output features. The data provisioning implementation is part of the model code.
Feature stores can provide a reasonable intermediary stage that integrate data from upstream data sources and allow easy access for downstream training pipelines while possibly fostering feature reuse across teams. Depending on the application, it might be useful to maintain a multi-stage pipeline that distinguishes between model-specific data preprocessing on the hand, and upstream reusable cross-application datasets on the other hand. The feature store could therefore act as experiment-specific cache, or a central location for access and discovery, or both. Feature stores are not a certain technology but an architectural role which is played by something otherwise referred to as a database.
Over time, the data’s structure and the pool of examples are subject to change. Therefore, to ensure exact reproducibility, a concept for data versioning needs to be in place that to re-access or re-fetch the same dataset and creating the same data splits, even if the source data pools have changed. This allows debugging, testing, re-creating a model in production after model evolution, and separating between data pipelines for models in production and models under development, e. g. with new features.
To ensure that retraining a model over time does not worsen a model’s quality due to unexpected changes in data, it is necessary to validate assumptions against the dataset.
Continuous Training
MLOps infrastructure should allow finding the best model parameters for a specified feature dataset and the released model code artifact, using an automated pipeline that comprises steps for automated training, hyperparameter configuration tuning, and evaluation based on test set metrics and test cases. The training implementation, tuning, and evaluation is part of the model code, even though it might be necessary that the model code artifact complies to an interface required by the pipeline orchestrator.
The training pipeline allows for experiment logging and tracking and distributed training, in particular for multi-GPU training. Triggers for retraining a model include on-demand invocation, time-based scheduling, availability of new data, availability of a new model code, model performance degradation, and changes in statistical properties of the data.
The training pipeline outputs a serialized model, comprising its structure and parameters. Depending on the concrete application design, the serialized could require application-specific mode code for inference, or rely on framework code only. The serialized model and information on the execution including the hyperparameters, the evaluation results, and possibly a reference to the versioned dataset are persisted in a model store.
Continuous Model Delivery
MLOps infrastructure should allow promoting serialized models from the model store to production by packaging and releasing them as an executable or as a dependency for on-device deployment, for deployment as a service or deployment as a short-running or long-running job. Deployments could follow a phased roll-out where new model version are only acessible to a subset of model consumers. Through model monitoring, the performance as estimated by the model evaluation using the test dataset, should be continuously compared to the actual performance. Drift detections can help to warn early against declining performance, thus triggering a retraining or indicating a model code update. For deployment as a service, a backend-based approach monitoring must be installed. For on-device deployment, monitoring must be realized through a dedicated feedback loop.
-
Sato, Wider, Windheuser 2019. Continuous Delivery for Machine Learning. https://martinfowler.com/articles/cd4ml.html ↩︎